We are excited to announce the release of sibships in the Berkeley Unified Numident Mortality Database (BUNMD) and CenSoc-Numident dataset.
Sibling comparisons are a useful tool that allow researchers to control for shared, unmeasured confounding variables. However, sibling relationships are not identified in administrative mortality data, and are difficult to establish in census data if siblings are not residing in the same household. In order to identify siblings in the BUNMD and CenSoc-Numident (which links the BUNMD with the 1940 Census), we use parents’ names as listed in Social Security Numident records. Specifically, individuals must agree on four name variables to be declared siblings: father’s first name, father’s last name, mother’s first name, and mother’s last (maiden/unmarried) name.
We use two strategies to match siblings:
- The exact match method identifies siblings only with exactly identical parent names (after names have undergone cleaning and standardization).
- The flexible match method permits parents’ names to be slightly different, within a threshold defined by Jaro–Winkler string distance, in addition to exact matches. This allows siblings to be matched even in cases of minor misspellings, mistranscriptions, or spelling variations in parents’ names among sibships (e.g., mother’s maiden name recorded as “Brannum” and “Branum”). This increases the number of siblings found, but has higher potential to falsely match unrelated individuals. Most (but not all) individuals and sibling connections identified using the exact match method are also identified using this method.
The resulting sibships are among people who died at 65+ in the years 1988-2005, may be of any gender composition, and contain from 2-9 siblings (BUNMD) or 2-8 siblings (CenSoc-Numident). An overview of the siblings identified for each CenSoc dataset and matching method is below:
| Dataset | Method | N Sibships | N Individuals |
| BUNMD | Exact | 2.13 million | 4.77 million |
| BUNMD | Flexible | 2.71 million | 6.12 million |
| CenSoc-Numident | Exact | 427 thousand | 908 thousand |
| CenSoc-Numident | Flexible | 552 thousand | 1.19 million |
Sibships found using both matching strategies are highly concordant in characteristics that siblings would usually be expected to share, including birth state and race. And as these methods rely solely on parents’ names, sibling groups are not required to share a common surname, allowing sisters with differing married names to be matched to their siblings. However, a main limitations is that only individuals who both know and record all parent name variables can be matched to their siblings. Not all members of a sibship may be matched to each other, making precise sibship size and birth order uncertain.
These sibships open up numerous research possibilities with CenSoc data, such as the ability to easily study sibling differences in occupation, education, income, home value, and many other 1940 Census variables. Geographic variables from the census and Numident data may be used to examine migration and place-based exposures among siblings. In the figure below, we use the CenSoc-Numident sibship dataset to examine the educational attainment of 153 thousand adult sibling pairs in the 1940 Census:
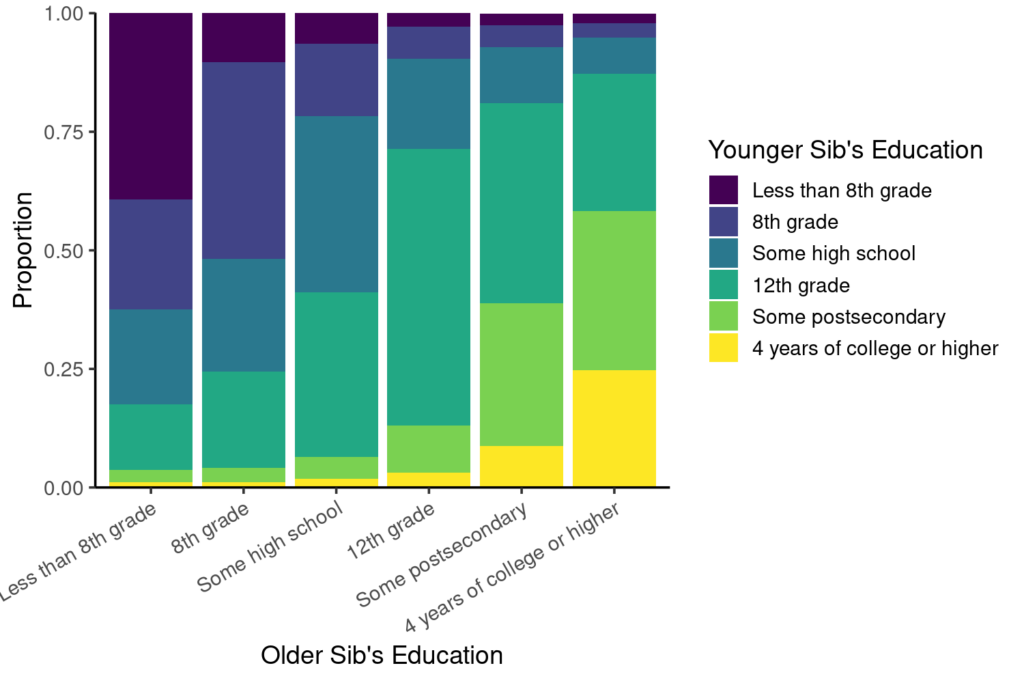
For a detailed description of matching methodology and quality of resulting data please refer to the technical documentation, Methods for Identifying Siblings in Administrative Mortality Data. Visit the CenSoc Data page for download links and codebooks.
Story by Maria Osborne. For inquiries, contact censoc@berkeley.edu